 O caso de Cambridge Analytica fornece a ocasião para observar mais de perto os métodos de funcionamento daquela autêntica arma de condicionamento das massas que é Facebook. A explicação chega do Proceedings of the National Academy of Sciences of the United States of America (PNAS), jornal oficial da Academia das Ciências dos EUA, que em 2012 publicou um interessante artigo com o título "Traços e atributos privados são previsíveis a partir de registros digitais de comportamento humano", assinado pelos pesquisadores Michal Kosinski, David Stillwell e Thore Graepel, todos da universidade de Cambridge (Reino Unido).
O caso de Cambridge Analytica fornece a ocasião para observar mais de perto os métodos de funcionamento daquela autêntica arma de condicionamento das massas que é Facebook. A explicação chega do Proceedings of the National Academy of Sciences of the United States of America (PNAS), jornal oficial da Academia das Ciências dos EUA, que em 2012 publicou um interessante artigo com o título "Traços e atributos privados são previsíveis a partir de registros digitais de comportamento humano", assinado pelos pesquisadores Michal Kosinski, David Stillwell e Thore Graepel, todos da universidade de Cambridge (Reino Unido).A questão é muito técnica, mas aqui vamos simplifica-la ao máximo, começando já pelas conclusões do estudo: no Facebook é possível ver não apenas as coisas que o usuário escreve, mas também as que o usuário não escreve. O artigo mostra aquele que é um fenómeno conhecido, a causalidade de Granger, e a sua aplicação à análise do comportamento humano a partir de informações mais ou menos aleatórias. Complicado? Não, vamos fazer um exemplo.
Digamos que o meu sistema informático de análise varre todos os produtos dum supermercado, sem saber nada além do que acontece no interior do prédio. O que o sistema nota é que quando no rótulo estiver escrito "tomates", no interior da embalagem há mesmo isso: tomates. O sistema não é um génio, mesmo assim consegue criar um método preditivo para todas as embalagens do supermercado. O método é simples: o rótulo determina o conteúdo das embalagens do supermercado. Atenção: segundo este método o rótulo não "descreve" mas "determina", "decide" o conteúdo. Eu disse que o sistema não é um génio: na verdade sabemos que não é o rótulo que determina o conteúdo da embalagem, o rótulo só o descreve.
Mas pasmem-se: este método funciona! O sistema de análise continua a ler os rótulos e, de facto, parece que todas as embalagens obedecem a quanto afirmado pelos rótulos. Lembram-se de ter dito que o sistema de análise não sabe o que se passa no exterior? Este é o ponto-chave: se o sistema pudesse espreitar, entenderia que há uma empresa que cola os rótulos nas embalagens "depois" destas terem sido enchidas. Mas o sistema não pode espreitar, sabe só o que acontece no supermercado, portanto do seu ponto de vista é o rótulo que "manda" na embalagem.
Agora vamos supor que o supermercado seja Facebook. Nós somos as embalagens e o nosso rótulo é tudo o que dissermos. Nós não somos simples tomates, somos muito mais complexos do que isso, portanto os nossos rótulos podem parecer uma confusão: conversas, fotografias, likes, etc. Tudo isso pode mandar em confusão o sistema de análise, pois com os tomates era muito mais simples (era só ler o rótulo!).
O que faz o sistema? Continua a fazer o seu trabalho: analisa. E com o tempo descobre que um certo conjunto de termos encontrados nos "rótulos" são consistentes com o facto de ser homossexual (este é só um exemplo!). Não é preciso que o rótulo diga expressamente "homossexual", o sistema aprendeu que o conjunto de termos determina que o interior da nossa embalagem seja constituído por um homossexual, mesmo que não declarado.
A percentagem de eficácia deste sistema? Elevada.
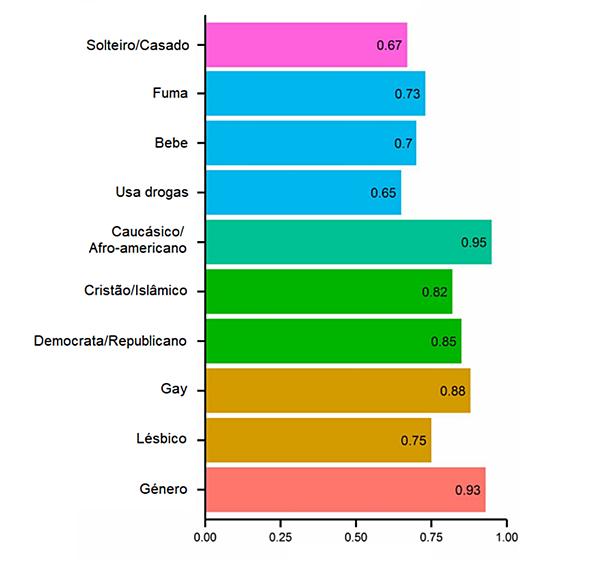
Isso significa que não estamos a falar dum problema de "simples" privacidade, não estamos a falar duma empresa que conhecia o conteúdo publicado pelos usuários. Estamos a falar duma empresa que sabe o que os usuários não escrevem. É isso que faz Facebook: pode inferir, depois de cerca de 300 likes, o que tínhamos decidido não publicar acerca de nós.

Quando Trump pediu para encontrar 200.000 pessoas que votariam nele se ele fosse amigo de israel, Cambridge Analytica não respondeu com coisas genéricas como "o teu eleitor-tipo é branco, desempregado, não muito educado": respondeu com uma série de nomes, sobrenomes, locais de residência, preferências, escolaridades, trabalhos, correios electrónicos, tudo capturado no Facebook. O que Trump teve que fazer foi simplesmente enviar-lhes uma carta simpática e bem feita para casa.
Acabou? Nem pensem: há o problema dos "influenciadores". Suponhamos que desejemos alcançar todos os eleitores, mas não temos certeza de que eles, mesmo após terem recebido a tal carta, decidam votar em Trump. Podemos pensar que uma boa coisa seria os eleitores ouvirem falar bem de nós, influencia-los com as palavras dos outros. Mas quem deveriam ouvir? Donde começar?
Calma: está aqui Facebook. Tudo o que temos que fazer é encontrar early adopters, isso é, pessoas que mergulham em cada novidade e que, muitas vezes, fazem tendência. Os early adopters têm uma boa openess, ou seja abertura mental: e esta característica também pode ser obtida da análise dos dados de Facebook.

Uma vez obtido o apoio dum eraly adopter, outros eleitores são simplesmente "arrastados". Portanto não é preciso contactar directamente dezenas de milhares de pessoas, pode ser suficiente falar com um punhado de early adopters. Não sabemos como Trump fez, talvez tenha entrado em contacto com algumas centenas de pessoas, mas não é nada que numa campanha presidencial não se faça: o jogo compensa.
Facebook em si (sem analisar as suas conexões com o poder) é uma empresa e como tal está baseada num negócio: mas esse negócio não é a rede social, é a publicidade (que gera lucros) e a recolha de dados (outros lucros). No Facebook tudo é gratuito porque é um canal que recolhe dados e distribui propaganda. A maioria dos usuários está absolutamente feliz em participar em pesquisas, preencher perfis, publicar interesses, entregar arquivos. A ideia é "Tanto não tenho nada a esconder".
Mas o caso da Cambridge Analytica demonstra duma vez por todas que o problema não é ter ou não algo a esconder; demonstra que Facebook afinal é mais do que uma empresa que vende publicidade; e deveria fazer entender de forma definitiva a importância da protecção dos dados pessoais. Perfis, reflexões, likes e outros itens aparentemente inocentes e privados são extraídos e reunidos numa base de dados explorada para fins eleitorais: isso é ainda mais aterrador do que se fossem usados para fins publicitários. São explorados os medos, as preocupações, os pontos fracos das pessoas; são criadas mensagens eleitorais personalizadas, que também alcançam aqueles que se consideram "independentes".
Em conclusão. É suficiente unir os pontinhos para entender a mensagem do escândalo Cambridge Analytica / Facebook: hoje as verdadeiras guerras para a primazia política no Ocidente são as guerras cibernéticas nas redes sociais. As empresas de marketing são usadas com meios estudados nas universidades; os manobradores ocultos são os grandes da Finança ou as corporações globais. Ninguém ainda lê o pensamento, mas a nossa mente pode ser perfilada, as nossas características escondidas podem ser encontradas e vendidas ao melhor oferente. É suficiente ter uma conta Facebook.
P.S.: Mas não tinham sido os russos a manipular as eleições?
Ipse dixit.
Fontes: PNAS: Private traits and attributes are predictable from digital records of human behavior





